

Deep learning is a new form of machine learning that has been used in a variety of fields including speech and image recognition, natural language processing, drug discovery, and recommended systems. In the past few years, deep learning is effective in malware detection and security in general.
Deep learning is based on a neural network that is a computational model inspired by the human brain. It is made up of a large number of interconnected nodes called neurons, each of which performs a simple mathematical operation. This operation, along with a set of node-specific parameters, determines the output of each neuron.
DL-MAFID scheme
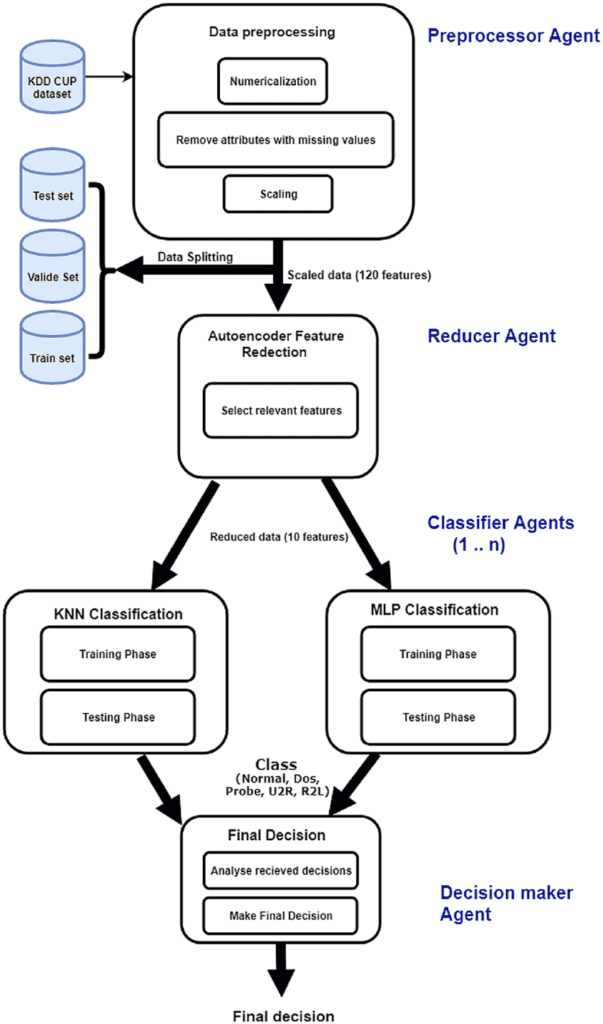
The main phases of the DL-MAFID process are preprocessing phase, feature reduction phase, and classification phase.
Preprocessing phase
The pre-processing phase aims to prepare the data so that the decision-making model can analyze it precisely.
The pre-processing phase in DL-MAFID is an important step in preparing the input data for analysis. It includes the following tasks:
- Data cleaning involves the removal of any irrelevant or missing data, as well as the correction of any errors or inconsistencies in the data.
- Data normalization entails scaling the data to a common range so that it can be compared and processed accurately by the decision-making model.
- Data transformation is the process of converting data into an analysis-ready format, such as encoding categorical data or converting text data to numerical data.
- Data splitting is the process of dividing data into training, validation, and test sets. The training data is used to train the decision-making model, the validation data to tune the model, and the test data to evaluate the model’s performance.
It’s important to note that, depending on the problem’s specific requirements, the pre-processing phase may include additional tasks.
The feature reduction phase in DL-MAFID
The feature reduction phase refers to the process of reducing the number of attributes or features used in the analysis. The purpose of this phase is to simplify the data and improve the decision-making model’s efficiency and accuracy.
The process of reducing the number of attributes or features used in the analysis is referred to as the feature reduction phase in DL-MAFID. The purpose of this phase is to simplify the data and improve the decision-making model’s efficiency and accuracy.
Several techniques can be used:
- Feature selection involves selecting a subset of the most relevant and significant attributes for analysis. This can be done manually by domain experts or by using algorithms such as mutual information or chi-squared tests.
- Feature extraction is the process of generating new features from combinations or transformations of the original features. This can improve the decision-making model’s interpretability and accuracy.
- Dimensionality reduction refers to the process of projecting data into a lower-dimensional space while retaining the most important information. Techniques such as principal component analysis (PCA), linear discriminant analysis (LDA), and t-distributed stochastic neighbor embedding can be used to accomplish this (t-SNE).
Classification phase
The classification phase is the process of assigning a category or label to a given instance based on its attributes. This is usually accomplished through the use of supervised machine learning, in which the decision-making model is trained on labeled data and then used to predict the class label of new instances.
Classification can be applied to a variety of issues, including image classification, text classification, and medical diagnosis. Classification techniques vary according to the type of data and the problem at hand, but some standard algorithms are:
- K-Nearest Neighbors (KNN)
- Logistic Regression
- Decision Trees
- Random Forests
- Support Vector Machines (SVM)
- Neural Networks
The final decision in DL-MAFID refers to the process of making a decision based on the results generated by the framework. This include:
- Evaluating the performance
- Selecting the best solution
- Visualizing the results
- Communicating the results
It is important to note that the final decision is not always simple, and the user may need to consider multiple factors and trade-offs before making a choice. The DL-MAFID framework offers an organized and data-driven approach to decision-making, but the final decision is left to the user.